在日常开发中,数据结构channel和select语句被高频使用,本文基于Go1.18.1版本的源码,探讨channel的底层数据结构和select访问Channel在编译期和运行时的底层原理
探讨底层原理是一个很奇妙却枯燥乏味的过程,希望读者您能保持足够的耐心,我们开始吧🤗
channel 的底层数据结构#
我们通过make关键字创建了一个缓冲区为5存储数据类型为int的channel
ch存储在栈上的一个指针,而指向的是堆上的hchan结构体
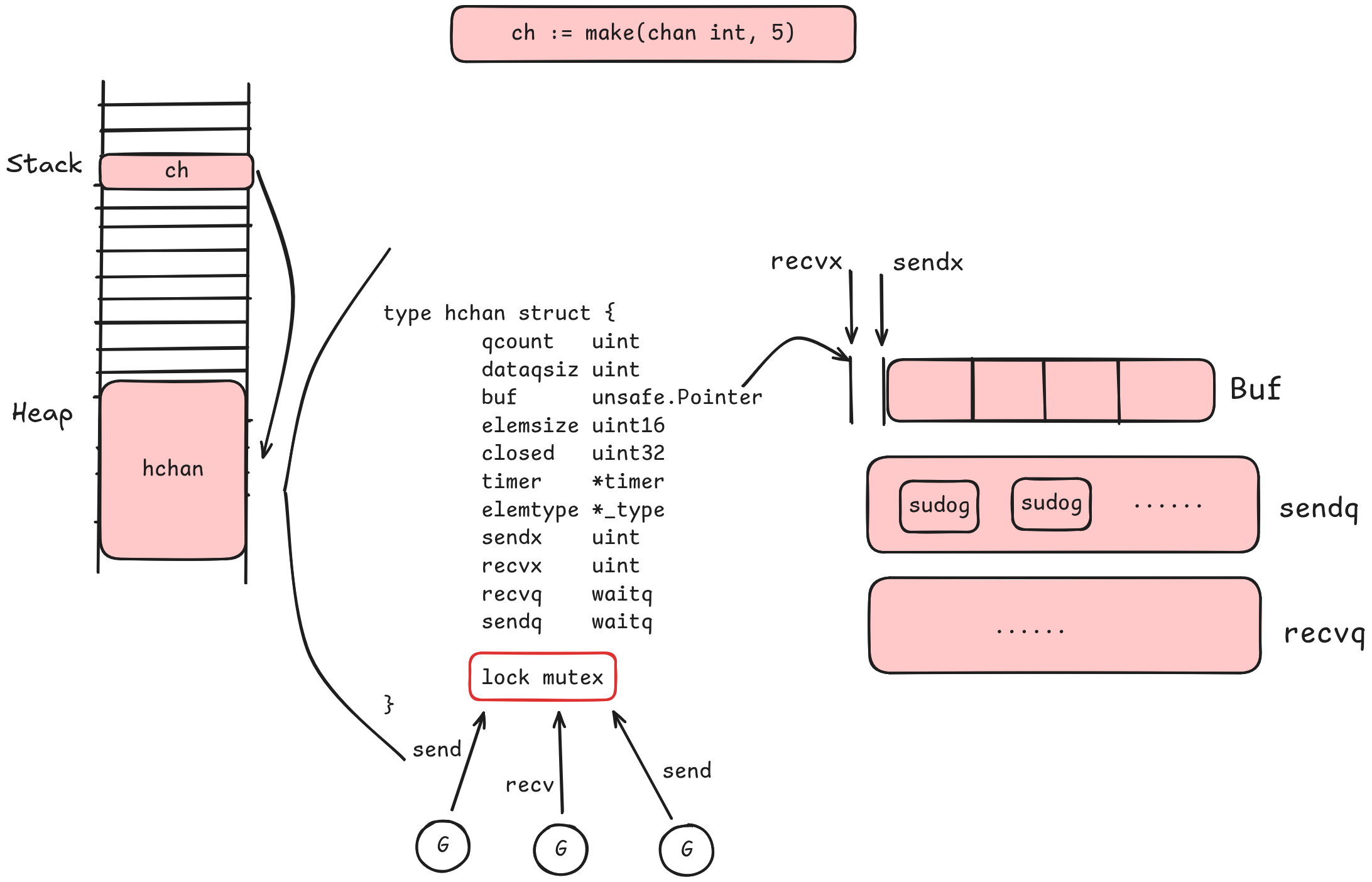 首先一个
首先一个channel需要能支持多个goroutine并发访问,这需要一把🔒(lock mutex)
对于有缓冲区的channel而言,需要知道缓冲区的位置(buf unsafe.Pointer)以及缓冲区内有多少个元素(qcount unit),每个元素多大(datasiz uint),所以缓冲区实际上就是一个数组
因为golang运行时中内存复制、垃圾回收等机制依赖数据的类型信息,所以还需要一个指针(elemtype *_type)指向数据的类型元数据
为了支持定时器的功能添加了timer *timer
channel支持交替的读写,需要分别记录读和写下标的位置(sendx uint recvx uint),当读和写不能立即完成的时候,需要能够让当前的goroutine在channel上等待,当条件满足时,需要可以立即唤醒等待中的goroutine,所有需要两个等待队列来针对读和写操作(sendq waitq recvq waitq)
channel支持被关闭(closed uint32)
综上所述,channel的底层数据结构就长这个样子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| type hchan struct {
qcount uint // total data in the queue
dataqsiz uint // size of the circular queue
buf unsafe.Pointer // points to an array of dataqsiz elements
elemsize uint16
closed uint32
timer *timer // timer feeding this chan
elemtype *_type // element type
sendx uint // send index
recvx uint // receive index
recvq waitq // list of recv waiters
sendq waitq // list of send waiters
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex
}
|
当我们创建一个有缓冲区的channel的时候,recvx和sendx都为0,不断往channel中发送数据的时候,因为没有goroutine在等待接收或发送数据,所以send会不断向后移动,最后移动回起点(recvx = sendx),那么这个时候则表明channel的缓冲区满了,其实channel的缓冲区是一个环形队列,也称之为环形缓冲区
那如果当缓冲区满了之后,goroutine还想往channel中发送数据,这个时候goroutine就会进入到发送等待队列sendq(这是一个sudog类型的链表),sudog中的g *g就记录该goroutine的信息,c *hchan记录着在等待哪个channel,elem unsafe.Pointer存储着数据指针。下面是截取的源码注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| type waitq struct {
first *sudog
last *sudog
}
type sudog struct {
// The following fields are protected by the hchan.lock of the
// channel this sudog is blocking on. shrinkstack depends on
// this for sudogs involved in channel ops.
g *g
next *sudog
prev *sudog
elem unsafe.Pointer // data element (may point to stack)
// The following fields are never accessed concurrently.
// For channels, waitlink is only accessed by g.
// For semaphores, all fields (including the ones above)
// are only accessed when holding a semaRoot lock.
acquiretime int64
releasetime int64
ticket uint32
// isSelect indicates g is participating in a select, so
// g.selectDone must be CAS'd to win the wake-up race.
isSelect bool
// success indicates whether communication over channel c
// succeeded. It is true if the goroutine was awoken because a
// value was delivered over channel c, and false if awoken
// because c was closed.
success bool
// waiters is a count of semaRoot waiting list other than head of list,
// clamped to a uint16 to fit in unused space.
// Only meaningful at the head of the list.
// (If we wanted to be overly clever, we could store a high 16 bits
// in the second entry in the list.)
waiters uint16
parent *sudog // semaRoot binary tree
waitlink *sudog // g.waiting list or semaRoot
waittail *sudog // semaRoot
c *hchan // channel
}
|
显然,当另外一个goroutine进来读取channel的数据,recvx向后移动,缓冲区又有了空间,这时会唤醒等待队列中的goroutine,让其执行写入数据的操作
到这里我们就认识到了channel底层的数据结构
发送数据到channel#
当channel的缓冲区满足以下条件才是不阻塞的:
- 缓冲区还有空闲位置
- 接收等待队列中还有阻塞等待的
goroutine
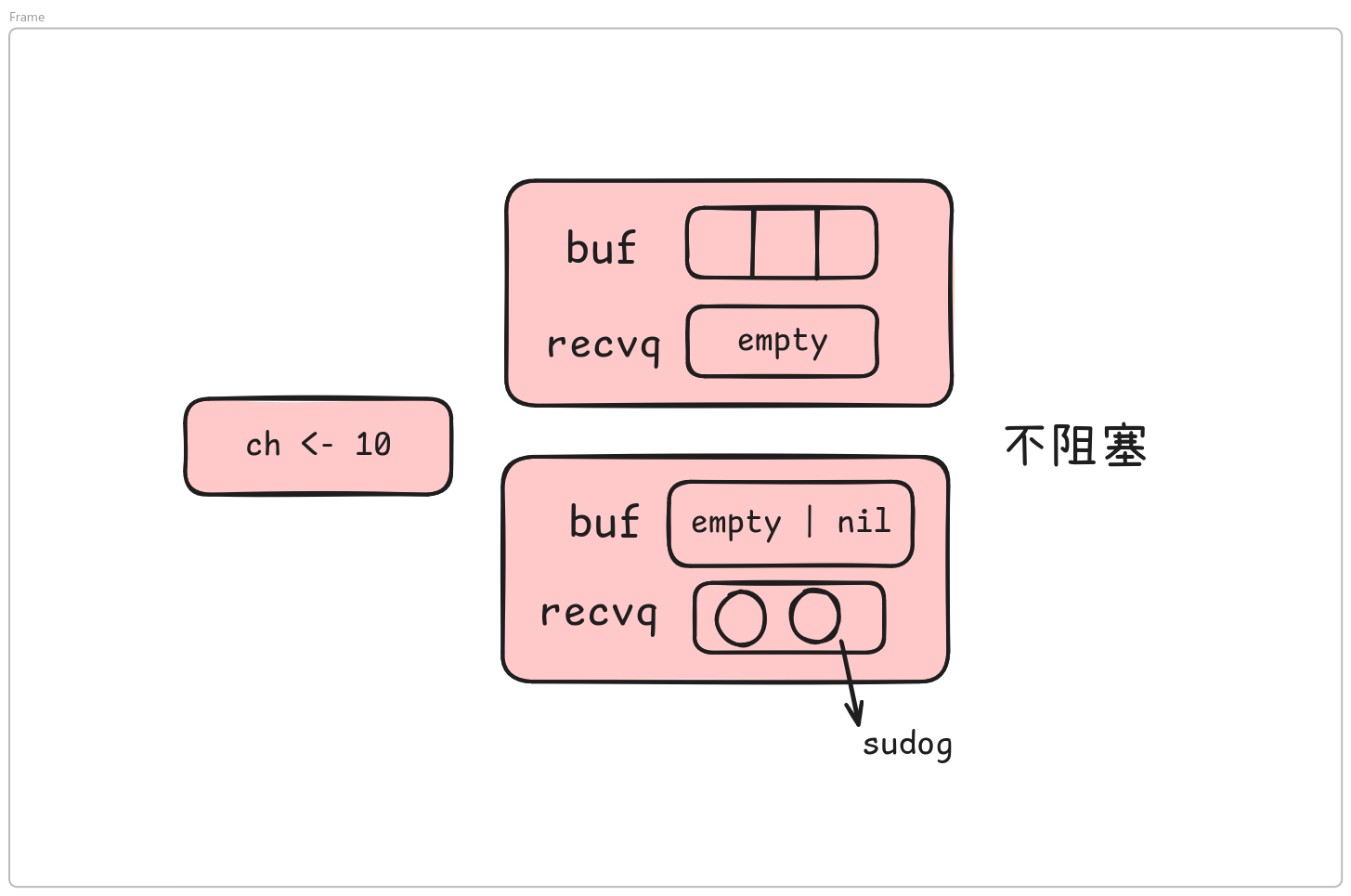
相反,阻塞的条件则是:
channel为nilchannel无缓冲区且接收队列中没有阻塞等待的goroutine- 缓冲区满了且接收队列中没有阻塞等待的
goroutine
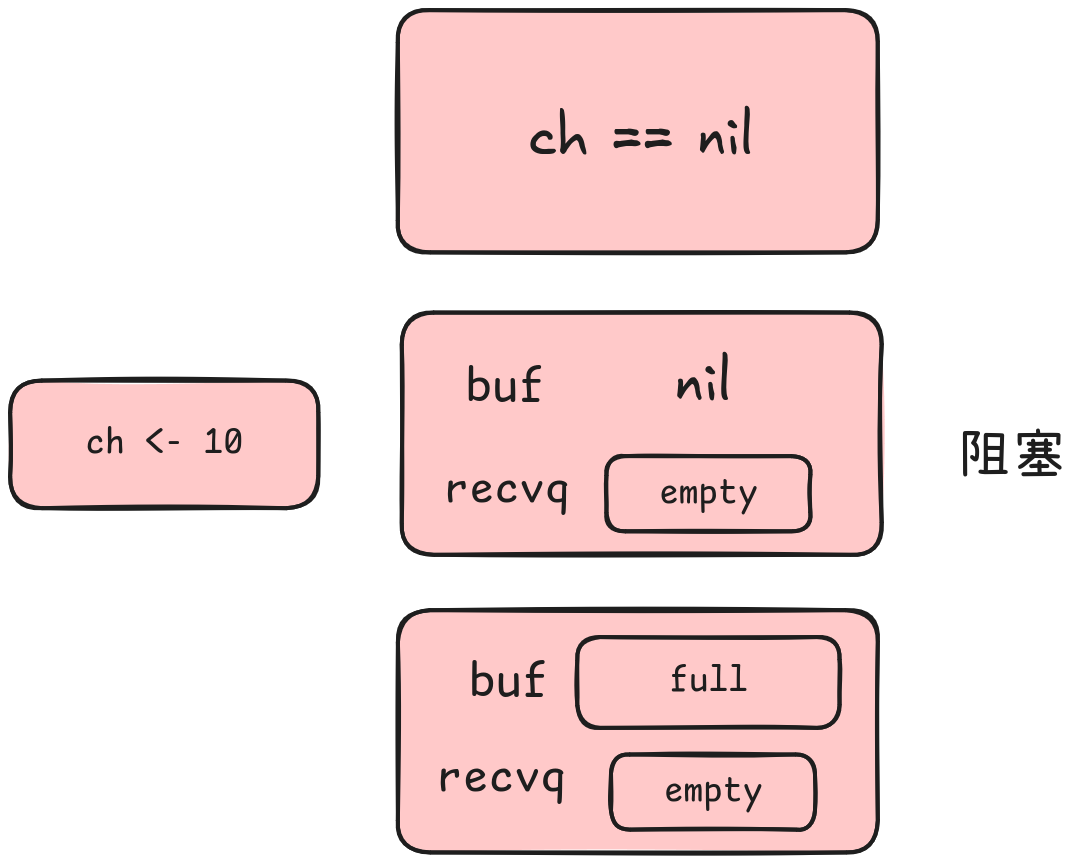
因此我们可以通过调整写代码的方式尽量不阻塞
允许阻塞式代码:
非阻塞式代码:
1
2
3
4
5
6
| select {
case ch <- 10:
...
default:
...
}
|
如果上面的case阻塞了,就会进入到default分支当中
这是发送数据的写法,接收数据的写法会更多一点
从channel中接收数据#
从channel中接收数据不阻塞:
- 缓冲区存在数据
- 没有缓冲区但是
sendq中有阻塞等待发送的goroutine
相反,阻塞的情况为:
channel为nil- 没有缓冲区且
sendq中没有阻塞等待发送的goroutine - 缓冲区为空且
sendq中没有阻塞等待发送的goroutine
允许阻塞式代码:
1
2
3
4
5
6
7
8
| // 丢弃ch中接收的数据
<-ch
// 将接收的数据赋值给v
v := <-ch
// Comma-ok风格写法
v, ok := <-ch
|
非阻塞式代码:
1
2
3
4
5
6
| select {
case <-ch:
...
default:
...
}
|
这里的select只针对但个channel的操作,多路select又有所不同
多路select#
多路select指的存在两个或更多的case分支,每个分支可以是一个channel的send和recv操作
golang的select语句采用的是多路复用的思想,本质上是为了达到通过一个协程同时处理多个IO请求(Channel读写事件)
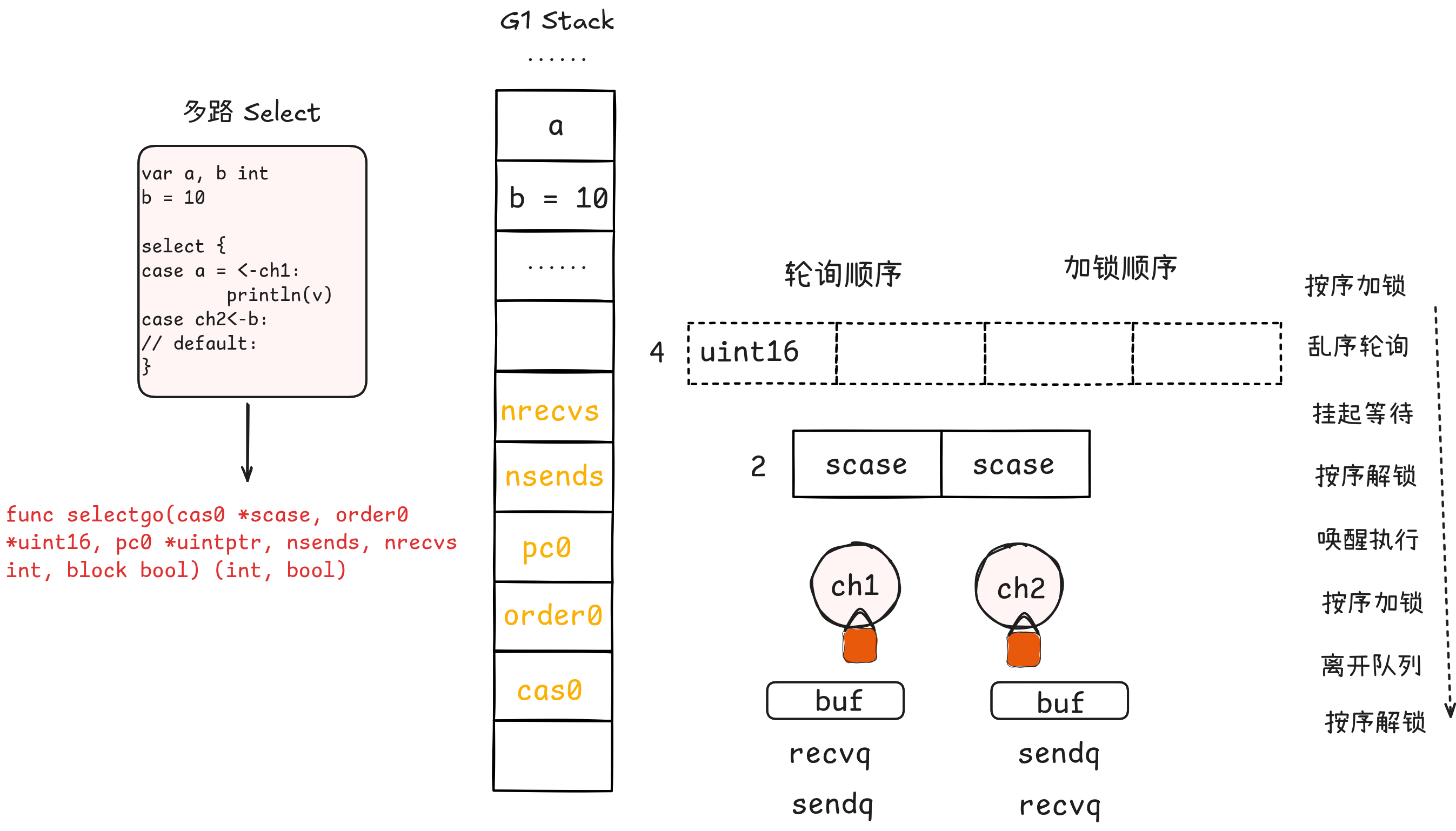
多路select会被golang编译器转化为对runtime.selectgo()的函数调用,由于该函数源码有四百多行,那我们先从函数的入参和出参看吧
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| // selectgo implements the select statement.
//
// cas0 points to an array of type [ncases]scase, and order0 points to
// an array of type [2*ncases]uint16 where ncases must be <= 65536.
// Both reside on the goroutine's stack (regardless of any escaping in
// selectgo).
//
// For race detector builds, pc0 points to an array of type
// [ncases]uintptr (also on the stack); for other builds, it's set to
// nil.
//
// selectgo returns the index of the chosen scase, which matches the
// ordinal position of its respective select{recv,send,default} call.
// Also, if the chosen scase was a receive operation, it reports whether
// a value was received.
func selectgo(cas0 *scase, order0 *uint16, pc0 *uintptr, nsends, nrecvs int, block bool) (int, bool)
|
cas0 *scase是一个数组,用于存储select的case分支
order0 *uint16指向的是一个类型为uint16的数组,其长度是分支数量的2倍,前面一半用于对每个channel的乱序轮询(保证公平性),后面一半用于有序的对每个channel加锁(合理的加锁顺序才能避免死锁)
pc0 *uintptr与golang的race检测相关 race-detector,这里不展开说
nsends, nrecvs int分别记录用于send和recv操作的分支分别有多少个
block bool表示是否阻塞,即有default为false,反之为true
我们来看一下执行过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
| func selectgo(cas0 *scase, order0 *uint16, pc0 *uintptr, nsends, nrecvs int, block bool) (int, bool) {
......
// 为了将scase分配到栈上,这里直接给cas1分配了64KB大小的数组,同理, 给order1分配了128KB大小的数组
cas1 := (*[1 << 16]scase)(unsafe.Pointer(cas0))
order1 := (*[1 << 17]uint16)(unsafe.Pointer(order0))
// ncases个数是发送chan个数nsends加上接收chan个数nrecvs
ncases := nsends + nrecvs
// scases切片是上面分配cas1数组的前ncases个元素
scases := cas1[:ncases:ncases]
// 顺序列表pollorder是order1数组的前ncases个元素
pollorder := order1[:ncases:ncases]
// 加锁列表lockorder是order1数组的第二批ncase个元素
// 所以说order0指向的数组是case数量的两倍,分成前一半和后一半使用
lockorder := order1[ncases:][:ncases:ncases]
......
// 生成排列顺序(避免 channel 的饥饿问题,保证公平性)
norder := 0
for i := range scases {
cas := &scases[i]
// 处理case中channel为空的情况
if cas.c == nil {
cas.elem = nil // 将elem置空,便于GC
continue
}
// 通过fastrandn函数引入随机性,确定pollorder列表中case的随机顺序索引
j := fastrandn(uint32(norder + 1))
pollorder[norder] = pollorder[j]
pollorder[j] = uint16(i)
norder++
}
pollorder = pollorder[:norder]
lockorder = lockorder[:norder]
// 根据chan地址确定lockorder加锁排序列表的顺序
// 通过简单的堆排序,以nlogn时间复杂度完成排序
for i := range lockorder {
j := i
// Start with the pollorder to permute cases on the same channel.
c := scases[pollorder[i]].c
for j > 0 && scases[lockorder[(j-1)/2]].c.sortkey() < c.sortkey() {
k := (j - 1) / 2
lockorder[j] = lockorder[k]
j = k
}
lockorder[j] = pollorder[i]
}
for i := len(lockorder) - 1; i >= 0; i-- {
o := lockorder[i]
c := scases[o].c
lockorder[i] = lockorder[0]
j := 0
for {
k := j*2 + 1
if k >= i {
break
}
if k+1 < i && scases[lockorder[k]].c.sortkey() < scases[lockorder[k+1]].c.sortkey() {
k++
}
if c.sortkey() < scases[lockorder[k]].c.sortkey() {
lockorder[j] = lockorder[k]
j = k
continue
}
break
}
lockorder[j] = o
}
......
}
|
加锁和解锁调用的是runtime.sellock()函数和runtime.selunlock()函数。从下面的代码逻辑中可以看到,两个函数分别是按lockorder顺序对channel加锁,以及按lockorder逆序释放锁。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| func sellock(scases []scase, lockorder []uint16) {
var c *hchan
for _, o := range lockorder {
c0 := scases[o].c
if c0 != c {
c = c0
lock(&c.lock)
}
}
}
func selunlock(scases []scase, lockorder []uint16) {
for i := len(lockorder) - 1; i >= 0; i-- {
c := scases[lockorder[i]].c
if i > 0 && c == scases[lockorder[i-1]].c {
continue
}
unlock(&c.lock)
}
}
|
接下来就是selectgo的主逻辑啦(好长😭)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
| func selectgo(cas0 *scase, order0 *uint16, pc0 *uintptr, nsends, nrecvs int, block bool) (int, bool) {
......
sellock(scases, lockorder)
......
// 阶段一: 查找可以处理的channel
var casi int
var cas *scase
var caseSuccess bool
var caseReleaseTime int64 = -1
var recvOK bool
for _, casei := range pollorder {
casi = int(casei) // case的索引
cas = &scases[casi] // 当前的case
c = cas.c
if casi >= nsends { // 处理接收channel的case
sg = c.sendq.dequeue()
// 如果当前channel的sendq上有等待的goroutine,就会跳到 recv标签并从缓冲区读取数据后将等待goroutine中的数据放入到缓冲区中相同的位置;
if sg != nil {
goto recv
}
if c.qcount > 0 { //如果当前channel的缓冲区不为空,就会跳到bufrecv标签处从缓冲区获取数据;
goto bufrecv
}
if c.closed != 0 { //如果当前channel已经被关闭,就会跳到rclose做一些清除的收尾工作;
goto rclose
}
} else { // 处理发送channel的case
......
if c.closed != 0 { // 如果当前channel已经被关闭就会直接跳到sclose标签,触发 panic 尝试中止程序;
goto sclose
}
sg = c.recvq.dequeue()
if sg != nil { // 如果当前channel的recvq上有等待的goroutine,就会跳到 send标签向channel发送数据;
goto send
}
if c.qcount < c.dataqsiz { // 如果当前channel的缓冲区存在空闲位置,就会将待发送的数据存入缓冲区;
goto bufsend
}
}
}
if !block { // 如果是非阻塞,即包含default分支,会解锁所有 Channel 并返回
selunlock(scases, lockorder)
casi = -1
goto retc
}
// 阶段2: 将当前goroutine根据需要挂在chan的sendq和recvq上
gp = getg()
if gp.waiting != nil {
throw("gp.waiting != nil")
}
nextp = &gp.waiting
for _, casei := range lockorder {
casi = int(casei)
cas = &scases[casi]
c = cas.c
// 获取sudog,将当前goroutine绑定到sudog上
sg := acquireSudog()
sg.g = gp
sg.isSelect = true
sg.elem = cas.elem
sg.releasetime = 0
if t0 != 0 {
sg.releasetime = -1
}
sg.c = c
*nextp = sg
nextp = &sg.waitlink
// 加入相应等待队列
if casi < nsends {
c.sendq.enqueue(sg)
} else {
c.recvq.enqueue(sg)
}
}
......
// 被唤醒后会根据 param 来判断是否是由 close 操作唤醒的,所以先置为 nil
gp.param = nil
......
// 挂起当前goroutine
gopark(selparkcommit, nil, waitReasonSelect, traceEvGoBlockSelect, 1)
// 加锁所有的channel
sellock(scases, lockorder)
gp.selectDone = 0
// param 存放唤醒 goroutine 的 sudog,如果是关闭操作唤醒的,那么就为 nil
sg = (*sudog)(gp.param)
gp.param = nil
casi = -1
cas = nil
caseSuccess = false
// 当前goroutine 的 waiting 链表按照lockorder顺序存放着case的sudog
sglist = gp.waiting
// 在从 gp.waiting 取消case的sudog链接之前清除所有元素,便于GC
for sg1 := gp.waiting; sg1 != nil; sg1 = sg1.waitlink {
sg1.isSelect = false
sg1.elem = nil
sg1.c = nil
}
// 清楚当前goroutine的waiting链表,因为被sg代表的协程唤醒了
gp.waiting = nil
for _, casei := range lockorder {
k = &scases[casei]
// 如果相等说明,goroutine是被当前case的channel收发操作唤醒的
if sg == sglist {
// sg唤醒了当前goroutine, 则当前G已经从sg的队列中出队,这里不需要再次出队
casi = int(casei)
cas = k
caseSuccess = sglist.success
if sglist.releasetime > 0 {
caseReleaseTime = sglist.releasetime
}
} else {
// 不是此case唤醒当前goroutine, 将goroutine从此case的发送队列或接收队列出队
c = k.c
if int(casei) < nsends {
c.sendq.dequeueSudoG(sglist)
} else {
c.recvq.dequeueSudoG(sglist)
}
}
// 释放当前case的sudog,然后处理下一个case的sudog
sgnext = sglist.waitlink
sglist.waitlink = nil
releaseSudog(sglist)
sglist = sgnext
}
}
// 最后的代码是循环第一阶段用到的跳转标签代码段
bufrecv:
......
recvOK = true
qp = chanbuf(c, c.recvx)
if cas.elem != nil {
typedmemmove(c.elemtype, cas.elem, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
selunlock(scases, lockorder)
goto retc
bufsend:
......
typedmemmove(c.elemtype, chanbuf(c, c.sendx), cas.elem)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
selunlock(scases, lockorder)
goto retc
recv:
// 可以直接从休眠的goroutine获取数据
recv(c, sg, cas.elem, func() { selunlock(scases, lockorder) }, 2)
......
recvOK = true
goto retc
rclose:
//从一个关闭 channel 中接收数据会直接清除 Channel 中的相关内容;
selunlock(scases, lockorder)
recvOK = false
if cas.elem != nil {
typedmemclr(c.elemtype, cas.elem)
}
......
goto retc
send:
......
// 可以直接从休眠的goroutine获取数据
send(c, sg, cas.elem, func() { selunlock(scases, lockorder) }, 2)
if debugSelect {
print("syncsend: cas0=", cas0, " c=", c, "\n")
}
goto retc
retc:
// 退出selectgo()函数
if caseReleaseTime > 0 {
blockevent(caseReleaseTime-t0, 1)
}
return casi, recvOK
sclose:
// 向一个关闭的 channel 发送数据就会直接 panic 造成程序崩溃;
selunlock(scases, lockorder)
panic(plainError("send on closed channel"))
|
总结一下
selectgo函数执行时会先按照有序的加锁顺序对所有的channel进行加锁
然后按照乱序的轮询顺序检查所有channel的等待队列和缓冲区,假如检查到某个channel有数据可操作,就会直接拷贝数据进入相应的case分支
如果所有的channel都不可操作,就把当前的协程添加到所有channel的sendq或recvq中
接着该协程会挂起,并解锁所有的channel
加入现在某个channel有数据可操作了,就会唤醒该协程进入case分支
完成对应分支的操作之后,会再次按照加锁顺序对所有channel进行加锁,然后从所有sendq或recvq中将自己移除
最后全部解锁后返回
编译器还对select做了哪些处理#
这里主要还想提到的是src/cmd/compile/internal/walk/select.go中的walkSelectCases()
该函数是对select不同case分支条件的处理,不同的情况会调用不同的运行时函数,如下图所示
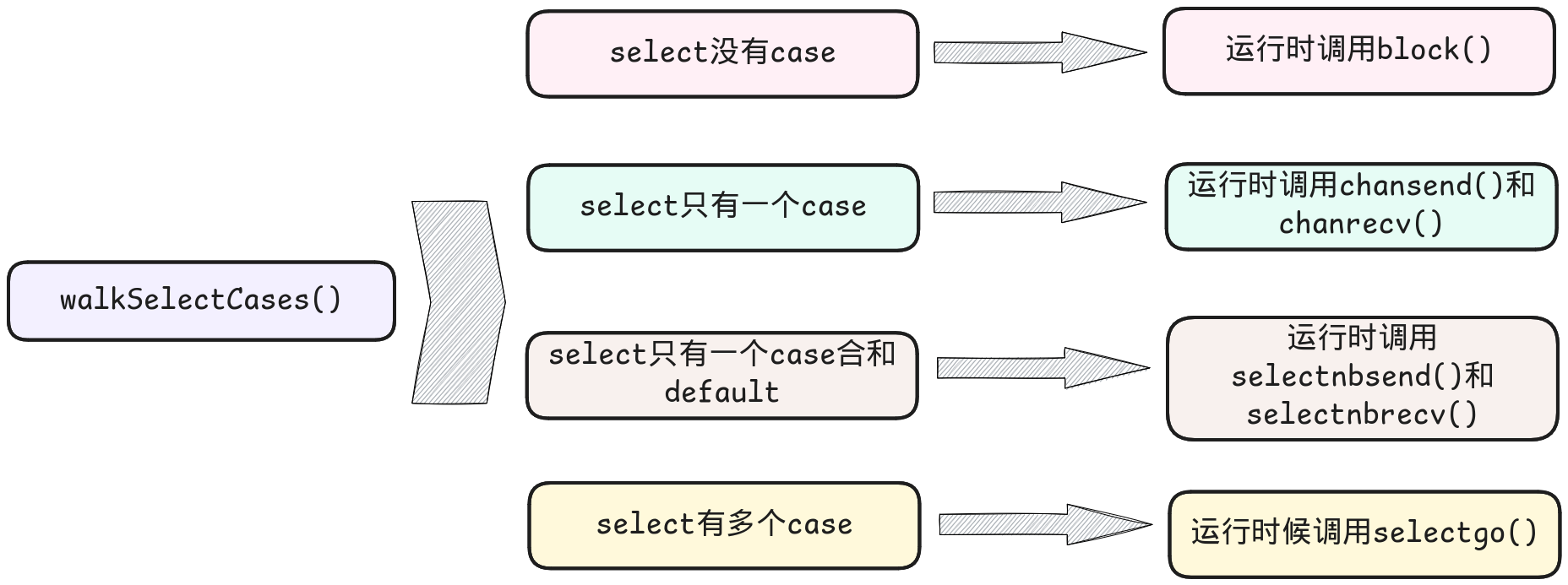
具体关于walkSelectCases()的源码就暂时不在这里展开啦
作为一名大二小白Gopher,文章存在有任何问题都可以联系我,当然也欢迎与我交流技术相关的问题,感谢你的阅读🤗